目录
部署架构
概要部署架构
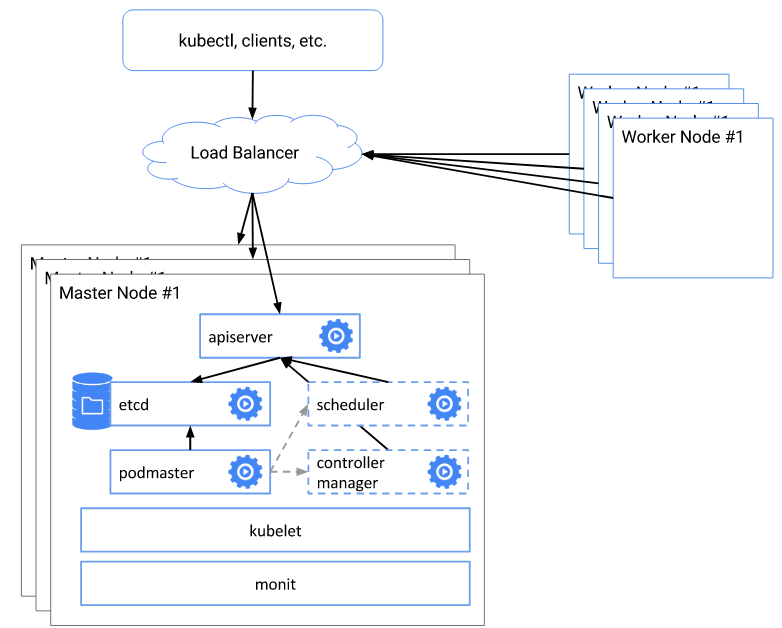
- kubernetes高可用的核心架构是master的高可用,kubectl、客户端以及nodes访问load balancer实现高可用。
详细部署架构
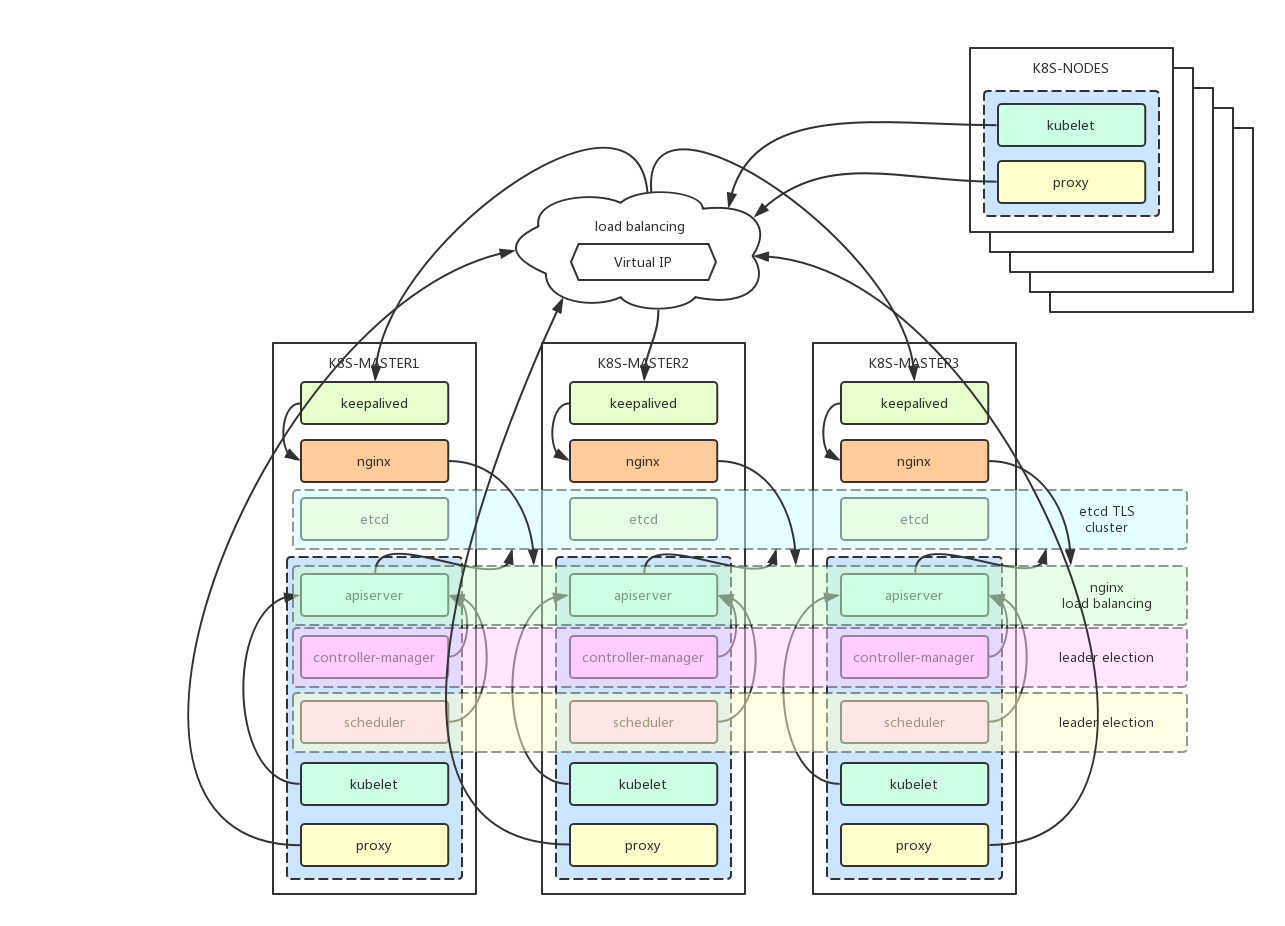
- kubernetes组件说明
kube-apiserver:集群核心,集群API接口、集群各个组件通信的中枢;集群安全控制;
etcd:集群的数据中心,用于存放集群的配置以及状态信息,非常重要,如果数据丢失那么集群将无法恢复;因此高可用集群部署首先就是etcd是高可用集群;
kube-scheduler:集群Pod的调度中心;默认kubeadm安装情况下–leader-elect参数已经设置为true,保证master集群中只有一个kube-scheduler处于活跃状态;
kube-controller-manager:集群状态管理器,当集群状态与期望不同时,kcm会努力让集群恢复期望状态,比如:当一个pod死掉,kcm会努力新建一个pod来恢复对应replicas set期望的状态;默认kubeadm安装情况下–leader-elect参数已经设置为true,保证master集群中只有一个kube-controller-manager处于活跃状态;
kubelet: kubernetes node agent,负责与node上的docker engine打交道;
kube-proxy: 每个node上一个,负责service vip到endpoint pod的流量转发,当前主要通过设置iptables规则实现。
- 负载均衡
keepalived集群设置一个虚拟ip地址,虚拟ip地址指向k8s-master1、k8s-master2、k8s-master3。
nginx用于k8s-master1、k8s-master2、k8s-master3的apiserver的负载均衡。外部kubectl以及nodes访问apiserver的时候就可以用过keepalived的虚拟ip(192.168.60.80)以及nginx端口(8443)访问master集群的apiserver。
主机节点清单
| 主机名 | IP地址 | 说明 | 组件 |
|---|---|---|---|
| k8s-master1 | 192.168.60.71 | master节点1 | keepalived、nginx、etcd、kubelet、kube-apiserver、kube-scheduler、kube-proxy、kube-dashboard、heapster |
| k8s-master2 | 192.168.60.72 | master节点2 | keepalived、nginx、etcd、kubelet、kube-apiserver、kube-scheduler、kube-proxy、kube-dashboard、heapster |
| k8s-master3 | 192.168.60.73 | master节点3 | keepalived、nginx、etcd、kubelet、kube-apiserver、kube-scheduler、kube-proxy、kube-dashboard、heapster |
| 无 | 192.168.60.80 | keepalived虚拟IP | 无 |
| k8s-node1 ~ 8 | 192.168.60.81 ~ 88 | 8个node节点 | kubelet、kube-proxy |
安装前准备
版本信息
- Linux版本:CentOS 7.3.1611
1 | cat /etc/redhat-release |
- docker版本:1.12.6
1 | $ docker version |
- kubeadm版本:v1.7.0
1 | $ kubeadm version |
- kubelet版本:v1.7.0
1 | $ kubelet --version |
所需docker镜像
- 国内可以使用daocloud加速器下载相关镜像,然后通过docker save、docker load把本地下载的镜像放到kubernetes集群的所在机器上,daocloud加速器链接如下:
https://www.daocloud.io/mirror#accelerator-doc
- 在本机MacOSX上pull相关docker镜像
1 | $ docker pull gcr.io/google_containers/kube-proxy-amd64:v1.7.0 |
- 在本机MacOSX上获取代码,并进入代码目录
1 | $ git clone https://github.com/cookeem/kubeadm-ha |
- 在本机MacOSX上把相关docker镜像保存成文件
1 | $ mkdir -p docker-images |
- 在本机MacOSX上把代码以及docker镜像复制到所有节点上
1 | $ scp -r * root@k8s-master1:/root/kubeadm-ha |
系统设置
以下在kubernetes所有节点上都是使用root用户进行操作
在kubernetes所有节点上增加kubernetes仓库
1 | $ cat <<EOF > /etc/yum.repos.d/kubernetes.repo |
- 在kubernetes所有节点上进行系统更新
1 | $ yum update -y |
- 在kubernetes所有节点上关闭防火墙
1 | $ systemctl disable firewalld && systemctl stop firewalld && systemctl status firewalld |
- 在kubernetes所有节点上设置SELINUX为permissive模式
1 | $ vi /etc/selinux/config |
- 在kubernetes所有节点上设置iptables参数,否则kubeadm init会提示错误
1 | $ vi /etc/sysctl.d/k8s.conf |
- 在kubernetes所有节点上重启主机
1 | $ reboot |
kubernetes安装
kubernetes相关服务安装
- 在kubernetes所有节点上验证SELINUX模式,必须保证SELINUX为permissive模式,否则kubernetes启动会出现各种异常
1 | $ getenforce |
- 在kubernetes所有节点上安装并启动kubernetes
1 | $ yum search docker --showduplicates |
docker镜像导入
- 在kubernetes所有节点上导入docker镜像
1 | $ docker load -i /root/kubeadm-ha/docker-images/etcd-amd64 |
第一台master初始化
独立etcd集群部署
- 在k8s-master1节点上以docker方式启动etcd集群
1 | $ docker stop etcd && docker rm etcd |
- 在k8s-master2节点上以docker方式启动etcd集群
1 | $ docker stop etcd && docker rm etcd |
- 在k8s-master3节点上以docker方式启动etcd集群
1 | $ docker stop etcd && docker rm etcd |
- 在k8s-master1、k8s-master2、k8s-master3上检查etcd启动状态
1 | $ docker exec -ti etcd ash |
kubeadm初始化
- 在k8s-master1上修改kubeadm-init-v1.7.x.yaml文件,设置etcd.endpoints的${HOST_IP}为k8s-master1、k8s-master2、k8s-master3的IP地址。设置apiServerCertSANs的${HOST_IP}为k8s-master1、k8s-master2、k8s-master3的IP地址,${HOST_NAME}为k8s-master1、k8s-master2、k8s-master3,${VIRTUAL_IP}为keepalived的虚拟IP地址
1 | $ vi /root/kubeadm-ha/kubeadm-init-v1.7.x.yaml |
- 如果使用kubeadm初始化集群,启动过程可能会卡在以下位置,那么可能是因为cgroup-driver参数与docker的不一致引起
- [apiclient] Created API client, waiting for the control plane to become ready
- journalctl -t kubelet -S ‘2017-06-08’查看日志,发现如下错误
- error: failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: “systemd”
- 需要修改KUBELET_CGROUP_ARGS=–cgroup-driver=systemd为KUBELET_CGROUP_ARGS=–cgroup-driver=cgroupfs
1 | $ vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf |
- 在k8s-master1上使用kubeadm初始化kubernetes集群,连接外部etcd集群
1 | $ kubeadm init --config=/root/kubeadm-ha/kubeadm-init-v1.7.x.yaml |
- 在k8s-master1上修改kube-apiserver.yaml的admission-control,v1.7.0使用了NodeRestriction等安全检查控制,务必设置成v1.6.x推荐的admission-control配置
1 | $ vi /etc/kubernetes/manifests/kube-apiserver.yaml |
- 在k8s-master1上重启docker kubelet服务
1 | $ systemctl restart docker kubelet |
- 在k8s-master1上设置kubectl的环境变量KUBECONFIG,连接kubelet
1 | $ vi ~/.bashrc |
flannel网络组件安装
- 在k8s-master1上安装flannel pod网络组件,必须安装网络组件,否则kube-dns pod会一直处于ContainerCreating
1 | $ kubectl create -f /root/kubeadm-ha/kube-flannel |
- 在k8s-master1上验证kube-dns成功启动,大概等待3分钟,验证所有pods的状态为Running
1 | $ kubectl get pods --all-namespaces -o wide |
master集群高可用设置
复制配置
- 在k8s-master1上把/etc/kubernetes/复制到k8s-master2、k8s-master3
1 | scp -r /etc/kubernetes/ k8s-master2:/etc/ |
- 在k8s-master2、k8s-master3上重启kubelet服务,并检查kubelet服务状态为active (running)
1 | $ systemctl daemon-reload && systemctl restart kubelet |
- 在k8s-master2、k8s-master3上设置kubectl的环境变量KUBECONFIG,连接kubelet
1 | $ vi ~/.bashrc |
- 在k8s-master2、k8s-master3检测节点状态,发现节点已经加进来
1 | $ kubectl get nodes -o wide |
修改配置
- 在k8s-master2、k8s-master3上修改kube-apiserver.yaml的配置,${HOST_IP}改为本机IP
1 | $ vi /etc/kubernetes/manifests/kube-apiserver.yaml |
- 在k8s-master2和k8s-master3上的修改kubelet.conf设置,${HOST_IP}改为本机IP
1 | $ vi /etc/kubernetes/kubelet.conf |
- 在k8s-master2和k8s-master3上修改admin.conf,${HOST_IP}修改为本机IP地址
1 | $ vi /etc/kubernetes/admin.conf |
- 在k8s-master2和k8s-master3上修改controller-manager.conf,${HOST_IP}修改为本机IP地址
1 | $ vi /etc/kubernetes/controller-manager.conf |
- 在k8s-master2和k8s-master3上修改scheduler.conf,${HOST_IP}修改为本机IP地址
1 | $ vi /etc/kubernetes/scheduler.conf |
- 在k8s-master1、k8s-master2、k8s-master3上重启所有服务
1 | $ systemctl daemon-reload && systemctl restart docker kubelet |
验证高可用安装
- 在k8s-master1、k8s-master2、k8s-master3任意节点上检测服务启动情况,发现apiserver、controller-manager、kube-scheduler、proxy、flannel已经在k8s-master1、k8s-master2、k8s-master3成功启动
1 | $ kubectl get pod --all-namespaces -o wide | grep k8s-master2 |
- 在k8s-master1、k8s-master2、k8s-master3任意节点上通过kubectl logs检查各个controller-manager和scheduler的leader election结果,可以发现只有一个节点有效表示选举正常
1 | $ kubectl logs -n kube-system kube-controller-manager-k8s-master1 |
- 在k8s-master1、k8s-master2、k8s-master3任意节点上查看deployment的情况
1 | $ kubectl get deploy --all-namespaces |
- 在k8s-master1、k8s-master2、k8s-master3任意节点上把kubernetes-dashboard、kube-dns、 scale up成replicas=3,保证各个master节点上都有运行
1 | $ kubectl scale --replicas=3 -n kube-system deployment/kube-dns |
keepalived安装配置
- 在k8s-master、k8s-master2、k8s-master3上安装keepalived
1 | $ yum install -y keepalived |
- 在k8s-master1、k8s-master2、k8s-master3上备份keepalived配置文件
1 | $ mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak |
- 在k8s-master1、k8s-master2、k8s-master3上设置apiserver监控脚本,当apiserver检测失败的时候关闭keepalived服务,转移虚拟IP地址
1 | $ vi /etc/keepalived/check_apiserver.sh |
- 在k8s-master1、k8s-master2、k8s-master3上查看接口名字
1 | $ ip a | grep 192.168.60 |
- 在k8s-master1、k8s-master2、k8s-master3上设置keepalived,参数说明如下:
- state ${STATE}:为MASTER或者BACKUP,只能有一个MASTER
- interface ${INTERFACE_NAME}:为本机的需要绑定的接口名字(通过上边的
ip a命令查看) - mcast_src_ip ${HOST_IP}:为本机的IP地址
- priority ${PRIORITY}:为优先级,例如102、101、100,优先级越高越容易选择为MASTER,优先级不能一样
- ${VIRTUAL_IP}:为虚拟的IP地址,这里设置为192.168.60.80
1 | $ vi /etc/keepalived/keepalived.conf |
- 在k8s-master1、k8s-master2、k8s-master3上重启keepalived服务,检测虚拟IP地址是否生效
1 | $ systemctl restart keepalived |
nginx负载均衡配置
- 在k8s-master1、k8s-master2、k8s-master3上修改nginx-default.conf设置,${HOST_IP}对应k8s-master1、k8s-master2、k8s-master3的地址。通过nginx把访问apiserver的6443端口负载均衡到8433端口上
1 | $ vi /root/kubeadm-ha/nginx-default.conf |
- 在k8s-master1、k8s-master2、k8s-master3上启动nginx容器
1 | $ docker run -d -p 8443:8443 \ |
- 在k8s-master1、k8s-master2、k8s-master3上检测keepalived服务的虚拟IP地址指向
1 | $ curl -L 192.168.60.80:8443 | wc -l |
- 业务恢复后务必重启keepalived,否则keepalived会处于关闭状态
1 | $ systemctl restart keepalived |
- 在k8s-master1、k8s-master2、k8s-master3上查看keeplived日志,有以下输出表示当前虚拟IP地址绑定的主机
1 | $ systemctl status keepalived -l |
kube-proxy配置
- 在k8s-master1上设置kube-proxy使用keepalived的虚拟IP地址,避免k8s-master1异常的时候所有节点的kube-proxy连接不上
1 | $ kubectl get -n kube-system configmap |
- 在k8s-master1上修改configmap/kube-proxy的server指向keepalived的虚拟IP地址
1 | $ kubectl edit -n kube-system configmap/kube-proxy |
- 在k8s-master1上查看configmap/kube-proxy设置情况
1 | $ kubectl get -n kube-system configmap/kube-proxy -o yaml |
- 在k8s-master1上删除所有kube-proxy的pod,让proxy重建
1 | kubectl get pods --all-namespaces -o wide | grep proxy |
- 在k8s-master1、k8s-master2、k8s-master3上重启docker kubelet keepalived服务
1 | $ systemctl restart docker kubelet keepalived |
验证master集群高可用
- 在k8s-master1上检查各个节点pod的启动状态,每个上都成功启动heapster、kube-apiserver、kube-controller-manager、kube-dns、kube-flannel、kube-proxy、kube-scheduler、kubernetes-dashboard、monitoring-grafana、monitoring-influxdb。并且所有pod都处于Running状态表示正常
1 | $ kubectl get pods --all-namespaces -o wide | grep k8s-master1 |
node节点加入高可用集群设置
kubeadm加入高可用集群
- 在k8s-master1上禁止在所有master节点上发布应用
1 | $ kubectl patch node k8s-master1 -p '{"spec":{"unschedulable":true}}' |
- 在k8s-master1上查看集群的token
1 | $ kubeadm token list |
- 在k8s-node1 ~ k8s-node8上,${TOKEN}为k8s-master1上显示的token,${VIRTUAL_IP}为keepalived的虚拟IP地址192.168.60.80
1 | $ kubeadm join --token ${TOKEN} ${VIRTUAL_IP}:8443 |
部署应用验证集群
- 在k8s-node1 ~ k8s-node8上查看kubelet状态,kubelet状态为active (running)表示kubelet服务正常启动
1 | $ systemctl status kubelet |
- 在k8s-master1上检查各个节点状态,发现所有k8s-nodes节点成功加入
1 | $ kubectl get nodes -o wide |
- 在k8s-master1上测试部署nginx服务,nginx服务成功部署到k8s-node5上
1 | $ kubectl run nginx --image=nginx --port=80 |
- 在k8s-master1让nginx服务外部可见
1 | $ kubectl expose deployment nginx --port=80 --target-port=80 --type=NodePort |
至此,kubernetes高可用集群成功部署。