分布式系统
分布式系统由网络将不同的机器连接起来。
类型:
- C/S
- P2P(没有中心节点,整个系统功能完全是分布式完成的)
CAP理论:
- 多份数据的 一致性
- 系统的 可用性
- 容忍网络断开
CAP三者不可兼得。
分布式文件系统
GFS
- C/C++实现
- Google MapReduce的基础
HDFS
- GFS的开源实现
- 基于Java
- 应用层的文件系统(下面说明应用层文件系统和普通文件系统的不同)
普通文件系统,比如POSIX文件系统,本来就是OS内核的一部分,其对外提供系统调用。
而HDFS,要对其上内容进行操作,必须连接HDFS client,HDFS client完全是一个用户程序,其底层调用了普通文件系统提供的系统调用。
GFS的设计目标:
- 大块数据的顺序读
- 并行追加(append)
- 不支持修改(overwrite)操作,因此 一致性 的实现可以大大简化
GFS/HDFS系统架构
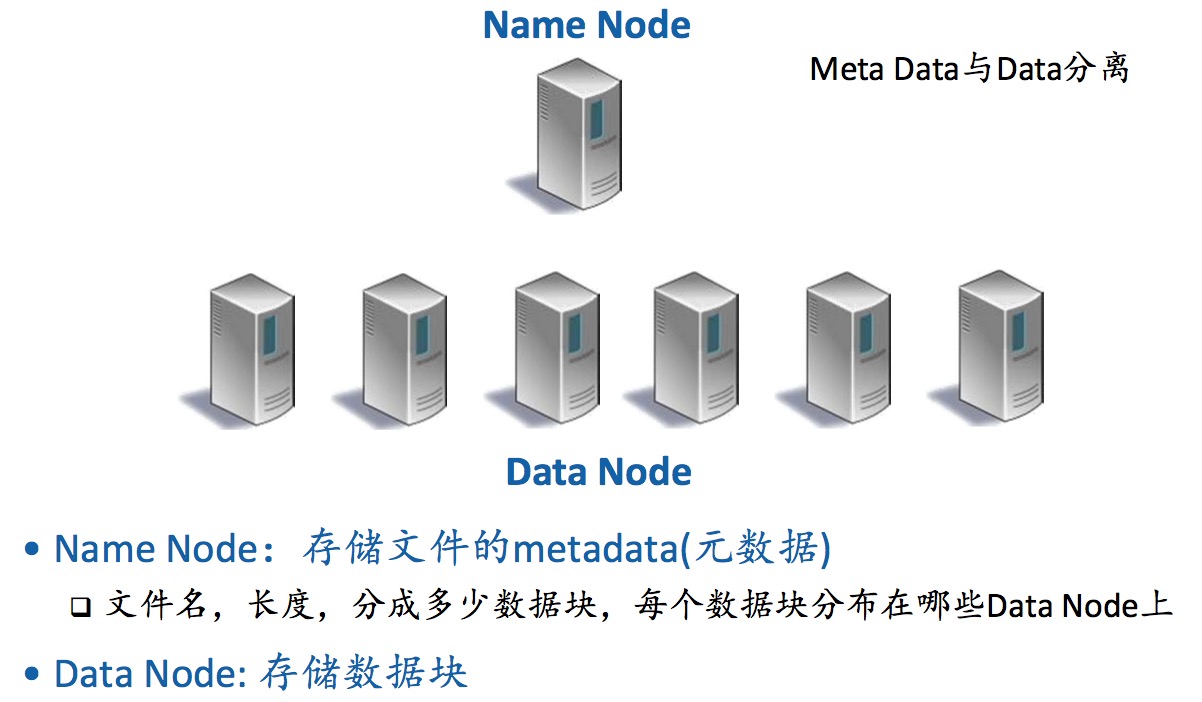
- 大文件切分成定长的数据块(默认64MB大小的数据块)
- 每个数据块独立地分布存储在DataNode上
- 默认每个数据块存储3份,在3个不同的DataNode上(提高可用性)
- 很好的顺序读性能
分布式存储(KV型)
NoSQL大部分是又互联网公司研发的,目标是支持本公司的某类重要的应用。关系型数据库不能满足特定的需求。
NoSQL往往是针对目标应用开发,简化了许多关系型数据库的功能,提高了系统性能、伸缩性等。不支持(完全的)SQL,不支持(完全的)ACID。
KV 型存储
KV 数据库通常是PUT和GET这两个操作。著名的KV型NoSQL有以下几个:
Amazon Dynamo
支持Amazon电商平台上运行的大量服务。比如,best sellers lists、购物车、session 管理等。
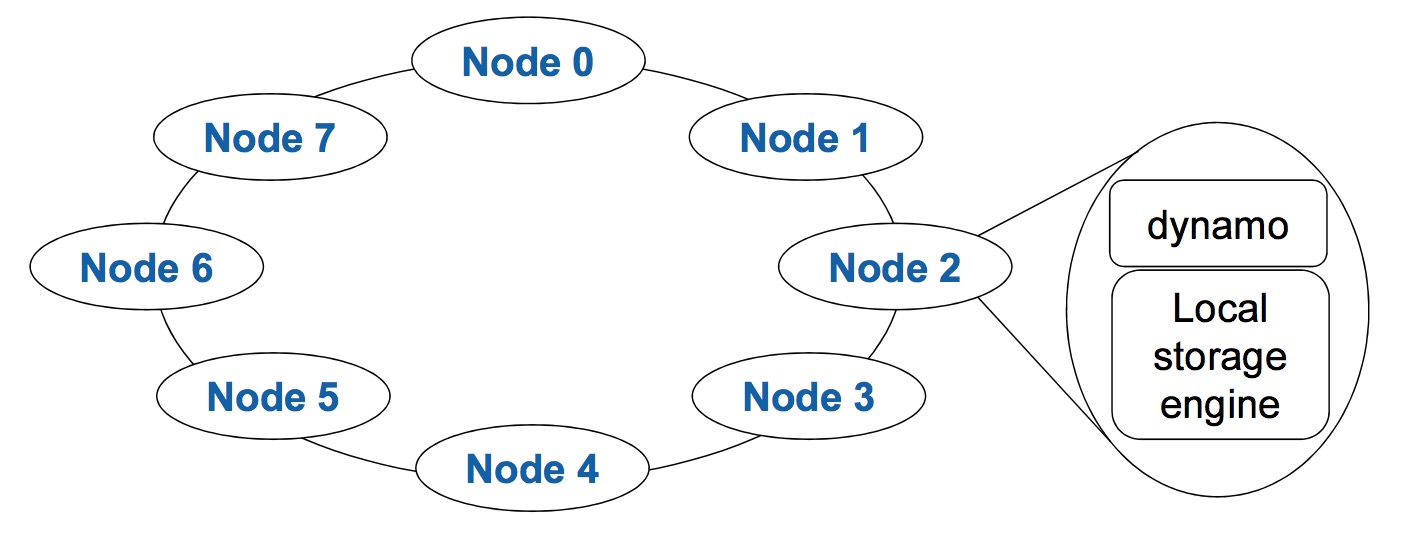
关键技术:一致性Hash算法。
备份:数据存储3份。
节点负载的问题:用 虚拟节点 解决。
Quorum机制(Quorum:翻译为法定人数):如果有N个副本,要求写的时候保证至少写了W个副本,要 求读的时候至少从R个副本读了数据,满足R+W>N,那么一定读到了最新的数据。R比较小,那么读的效率就越高;W比较小,那么写的效率就越高。
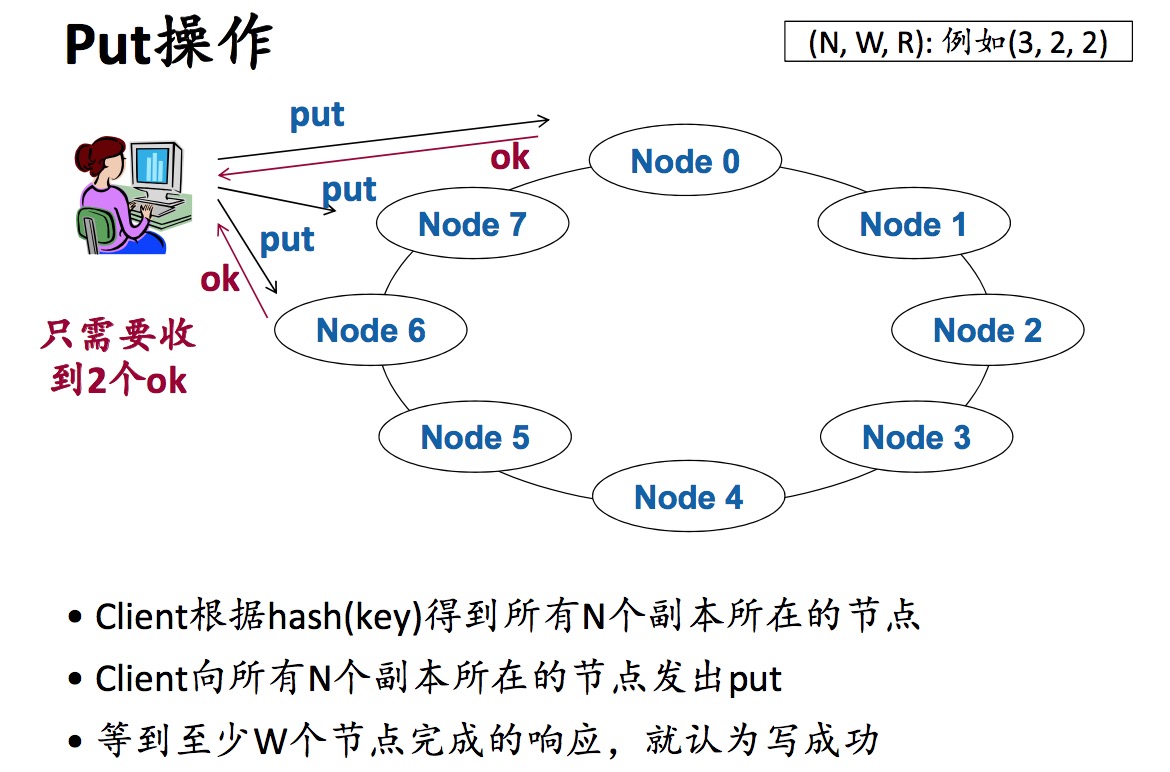
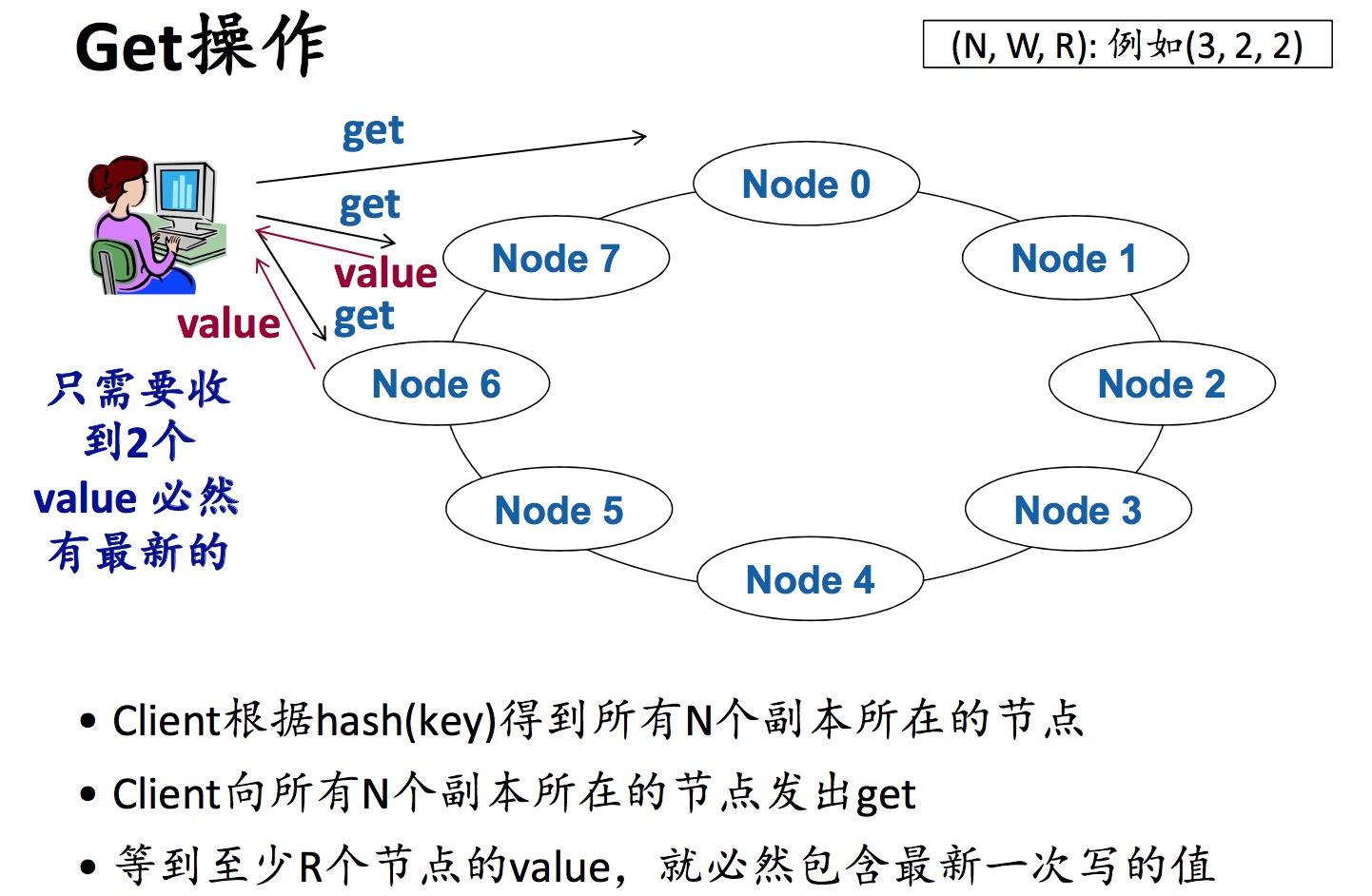
Quorum机制是一种 弱一致性 的解决方案。Put操作并没有等待所有N个节点全部写完成,可以提高写效率,增加系统性能。系统总会 最终 保证每个KV的N个副本都写成功,最终一致,但是不保证短时间内达到一致,最终可能需要很长的时间才能达到一致。
互联网应用,因为关系到用户体验,很多时候要更加注重 可用性(Availability)。
Google Bigtable/Apache HBase
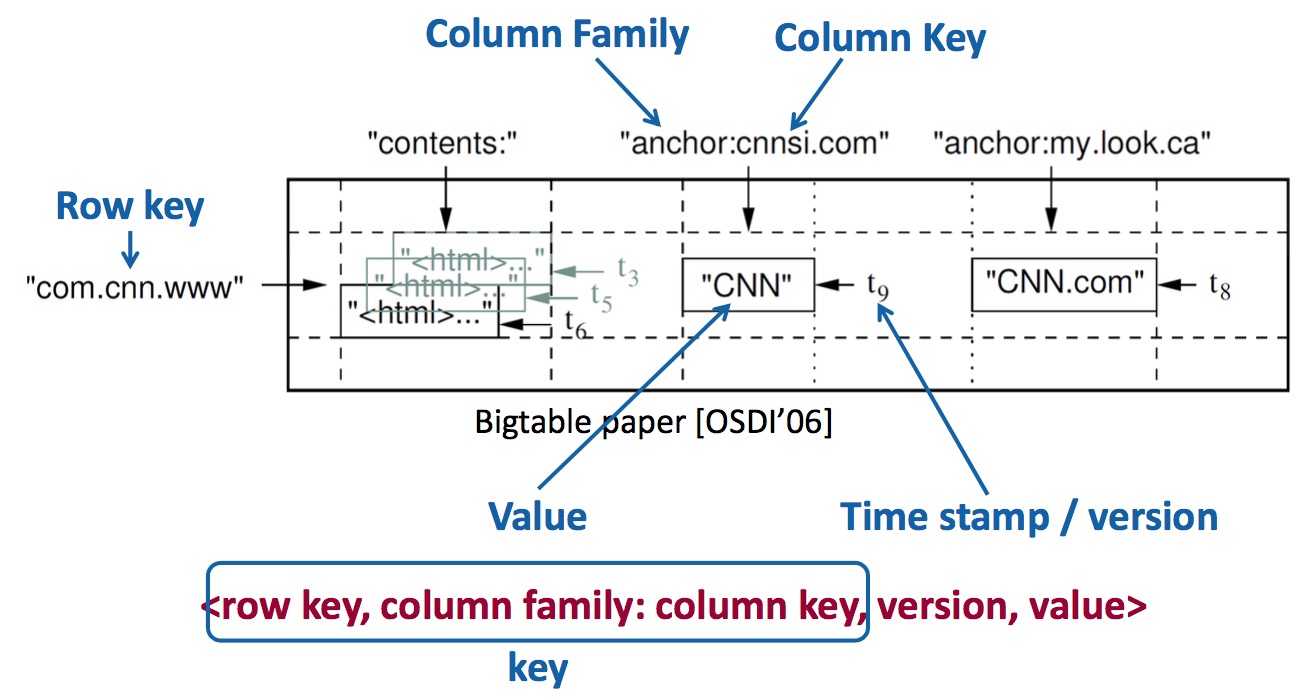
- Key = row key + column family + column key
- 所有row key是按顺序存储的
- 其中column又有column family前缀。Column family是需要事先声明的,种类有限(例如~10或~100),而column key可以有很多。
- 具体存储时,每个column family将分开存储(类似于列式数据库,见下图)
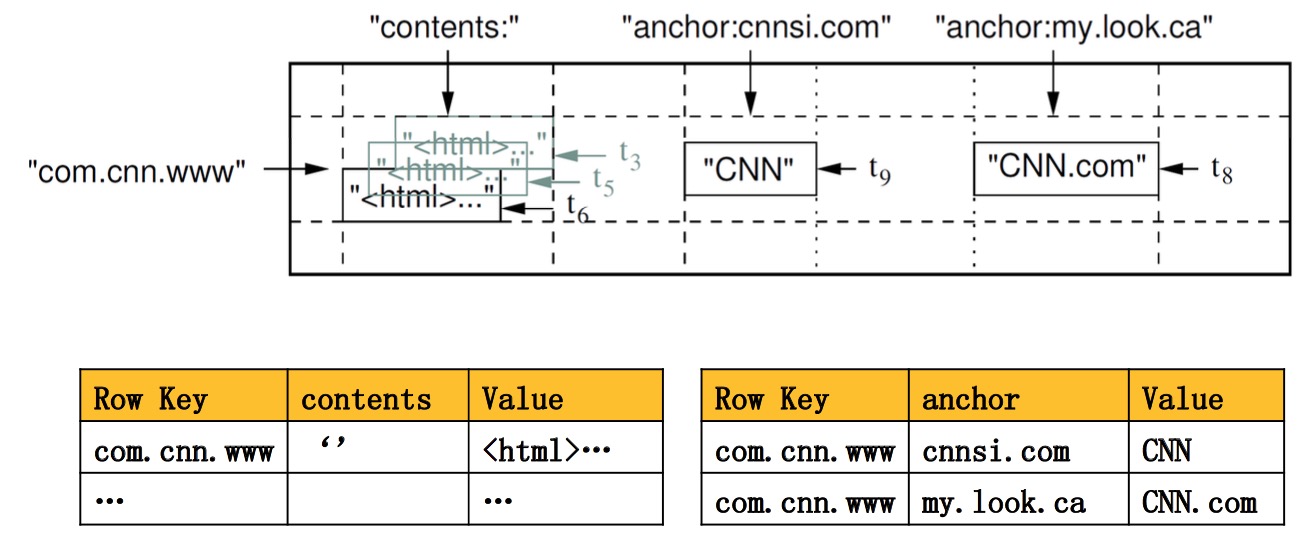
上图中的 contents 和 anchor 是 column family,cnnsi.com和my.look.ca是anchor这个column family下的column key。上图省略了timestamp。
BigTable/HBase 是基于 分布式文件系统 GFS/HDFS 的,分布式文件系统自动给其上NoSQL备份了3份副本。
Bigtable / Hbase 操作:
- Get:给定row key, column family, column key,读取value
- Put:给定row key, column family, column key,创建或更新value
- Scan:给定一个范围,读取这个范围内所有row key的value(Row key是排序存储的)
- Delete:删除一个指定的value
HBase的实时性还可以,Hive的实时性非常差。
HBase最常见的应用场景就是采集网页数据的存储。由于是KV结构,后来扩展到存 日志 也可以。
HBase还是算作是OLTP的NoSQL。
日志(Log)的作用:排错、Crash recovery。
分布式协同:ZooKeeper
文档存储系统
JSON:一种轻量级的数据交换存储格式。
Google Protocol Buffers:Google退出的一种轻便高效的结构化数据存储传输格式。
JSON vs. XML:XML没有JSON轻量级,标签很重
Apache Thrift:实现多语言的相互RPC调用
mongoDB:
- JSON是基本数据类型,存储为BSON二进制表示
- 名词
- Database ~ 关系型中的数据库概念
- Collection ~ 关系型中的table概念
- Document ~ 关系型中的记录概念
- 一个database包含多个collections, 每个collection包含多个documents。每个document的大小小于16MB
mongoDB 也支持简单的类似SQL的CRUD、聚合等操作,但是不支持join这种操作。
mongoDB集群
- 数据分片成多个shard
- 每个shard有多个副本
图存储系统
社交网络、地铁地图等的存储。
图数据存储系统
- 存储图的顶点和边
- 提供顶点和边的查询
Neo4j