MapReduce
MapReduce 是一个编程模型。
并行分布式程序设计非常不容易,涉及到很多方面:
- 多线程编程
- socket编程
- job的调度、协同、worker之间的负载均衡
- 节点的容错
- 分布式系统的debug比较困难
MapReduce的整体思路就是:让 程序员 写 串行程序,并行分布式计算平台提供一些接口(比如Map、Reduce),并将其并行分布式地执行。
MR计算平台的作用就是:
- 简化并行编程(编程时不需要思考并行的问题)
- 调试时只需要保证串行执行正确即可
MR数据模型:
- 数据由一条条记录构成
- 记录之间是无序的
- 每条记录有一个key,和一个value
- key:可以不唯一
- key和value的具体类型和内部结构由程序员决定,系统基本上把它们看作黑匣
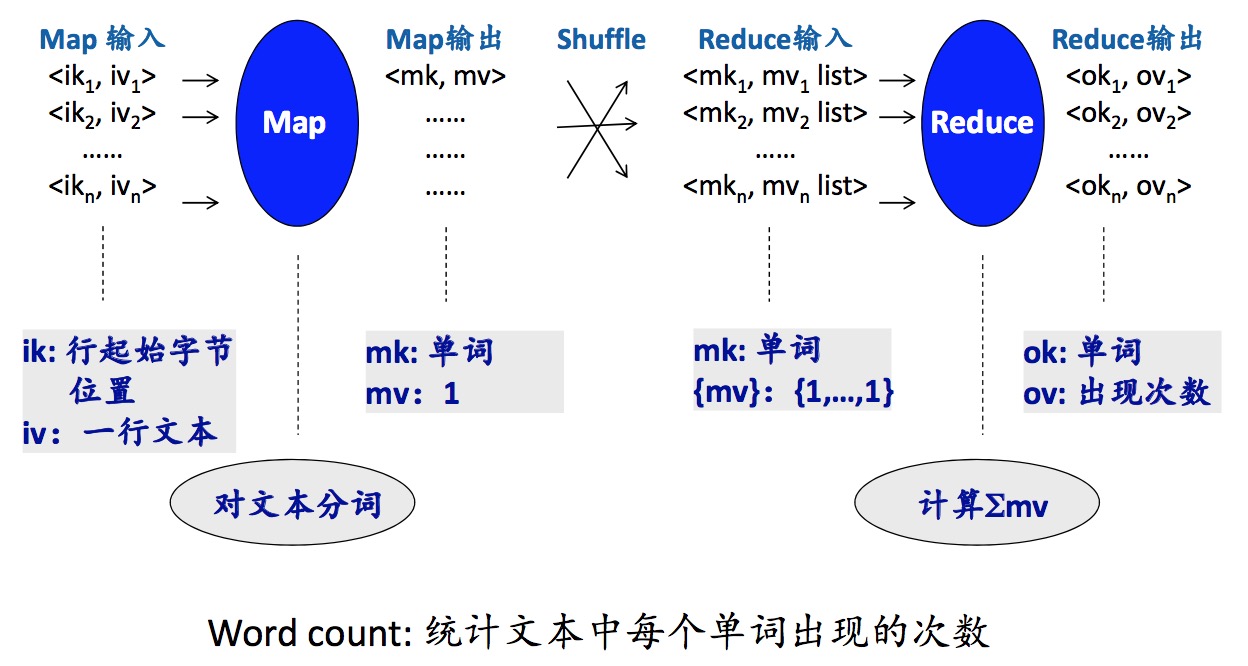
map-shuffle-reduce
word count 在mapper里面,程序员只要写统计 大文件 每行的每个词出现的频率即可,MR计算平台会自动地去map(将HDFS文件块输入到相应的TaskTracker)。shuffle起一个group by的作用,将map输出的结果相同的key的放到一起。然后在reducer里面,程序员只需要写将相同的key出现的次数相加即可,MR计算平台会自动地将上一步shuffle归并的结果(将相同key的
程序员只
MapReduce/Hadoop系统架构
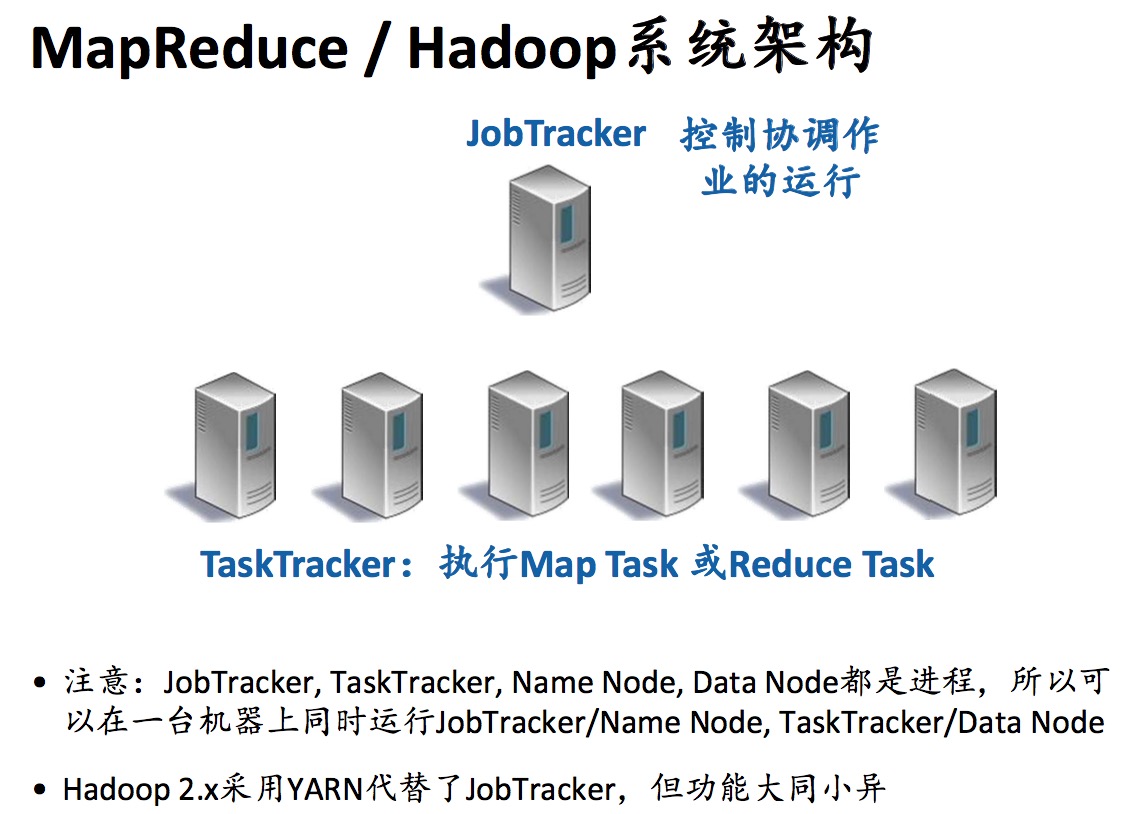
MR运行是基于HDFS的,用HDFS上读数据块(split)。
MR运行:提交作业(Job),包括Map函数、Reduce函数(Jar)、配置信息(例如,几个Mappers,几个 Reducers)、输入路径、输出路径等。
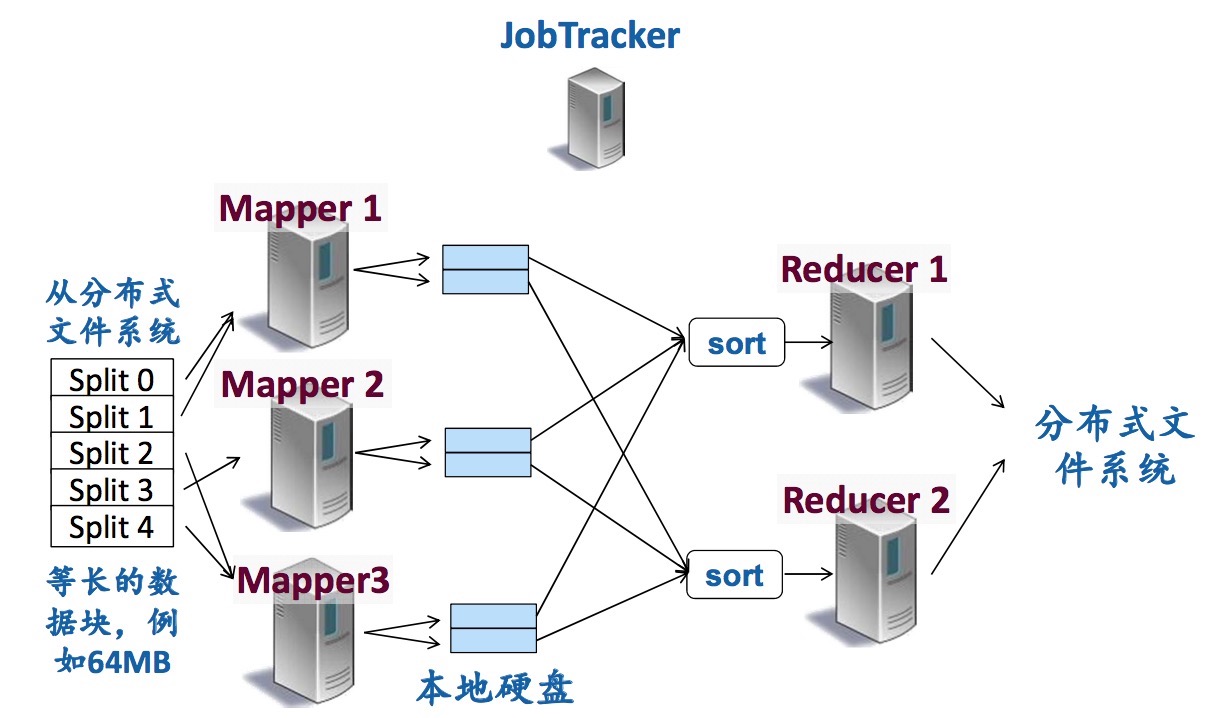
MR容错:
- 心跳机制:TaskTracker定期发送,向JobTracker汇报进度
- JobTracker可以及时发现不响应的机器或速度非常慢的机器。这些异常机器被称作Stragglers
- 一旦发现Straggler,JobTracker就将它需要做的工作分配给另一个worker
- Straggler是Mapper,将所对应的splits(HDFS文件块)分配给其它的Mapper
- Stragger是Reducer,在另一个TaskTracker执行这个Reducer
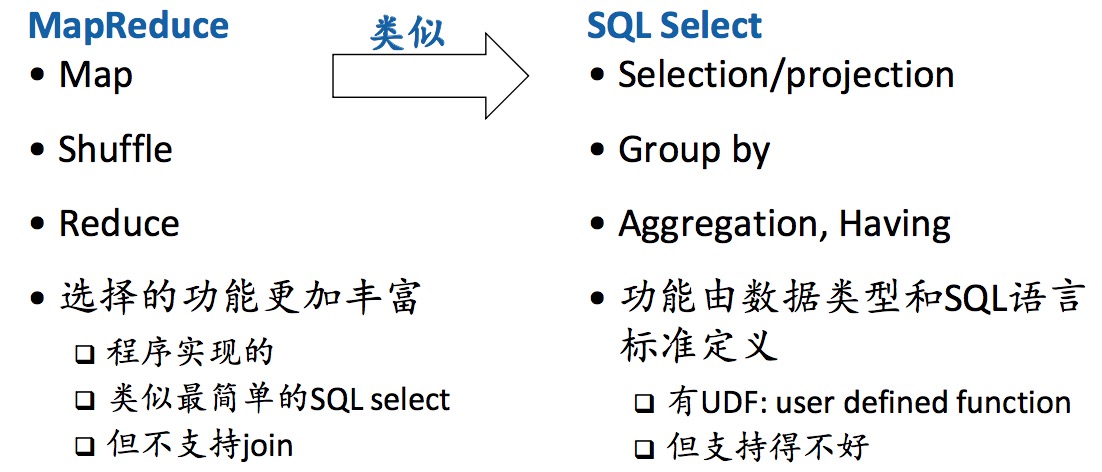
MapReduce+SQL
MapReduce 提供了一个并行分布式应用编写的 平台 ,大大简化了并行分布式编程。
- 程序员开发串行的 Map 和 Reduce 函数
- 在串行的环境开发和调试
- MR计算平台可以在成百上千个机器节点上并发执行MR程序,从而实现对大规模数据的处理
MapReduce+SQL系统在MR计算平台上增加了一层类似SQL的支持,方便一些查询分析操作。这类系统包括:
- Facebook Hive
- Yahoo Pig
- Microsoft Scope
Hive是目前被最广泛使用的MapReduce+SQL系统。
Hive的作用:
- 管理和处理结构化数据
- 在Hadoop基础上实现
- 提供类似SQL的HQL语言
- 数据存储在HDFS上。HDFS目录:
/usr/hive/warehouse/ - Table:一个单独的HDFS目录,
/user/hive/warehouse/表名 - Table可以进一步划分为Partition
- Partition可以进一步划分为Bucket
HQL,Hive会将其转换成MR程序执行。
MetaStore
- 存储表的定义信息等
- 默认在本地
${HIVE_HOME}/metastore_db中,也可以配置存储在数据库RDBMS中
Hive CLI(命令行客户端,可以执行各种HQL命令)
Hive数据模型:关系型表 + 扩展。
1 | CREATE TABLE status_updates( |
ds是partition key, hr是bucket key 它们都不包括在table schema中。
Hive在 关系型表 上的扩展
- 关系型表的列只能是 原子类型,而Hive表的列可以是更加复杂的数据类型(比如ARRAY、MAP、STRUCT)
- Hive可以直接读取已有的外部数据(比如,从Hive里读MySQL的数据,但是没有将MySQL中的数据导入到Hive里面)
1 | CREATE TABLE t1( |
Partition 使用举例
1 | INSERT OVERWRITE TABLE status_updates PARTITION(ds='2009-01-01', hr=12) |
然后,会在如下的子目录中,存储select的输出:
/user/hive/warehouse/status_updates/ds=2009-01-01/hr=12
ds是 partition key,所以 Hive 只使用对应的子目录中的数据。
Hive select 支持的操作:filter、aggregation(聚合)、简单的join。
Hive 主要的用户就是统计分析操作。Facebook 在生产环境中每天要跑上万个Hive Job。Hive 使 Hadoop 一些和SQL相关的操作化简了,非程序员也完全可以使用Hive。大多数的Hadoop Job都是Hive Job。跑这些 Hive Job 大多时候是用来生成相关报表,支持决策的。
内存计算
随着内存容量的越来越大,越来越大的数据集可以完全存在在内存中。
内存处理的优点:去除了硬盘IO的开销,极大地提高的速度。
内存KV数据库
Memcached:只提供简单的KV结构,内存利用率高一些
Redis:提供更加丰富的数据类型,RDB快照和AOF日志功能保证数据的可靠性。Redis是单线程的,一个Redis实例只能利用一个核。
Facebook 的 MySQL + Memcached 结构。
大多数场景,数据库90%+是读操作,写操作非常少,使得缓存、读写分离这些机制得以应用。
访问数据先看缓存中有没有,有的话访问缓存直接拿数据,否则访问MySQL中记录,然后将其放到Memcached缓存中,如果MySQL中数据变化,同步commit log将相应的缓存失效。使用LRU作缓存替换策略。
Memcached 更像是一种纯粹的缓存,而Redis则更像是一种基于内存的数据库。
内存MapReduce
Spark:面向大数据分析的内存系统
- SparkSQL
- SparkStreaming
- MLlib
- GraphX
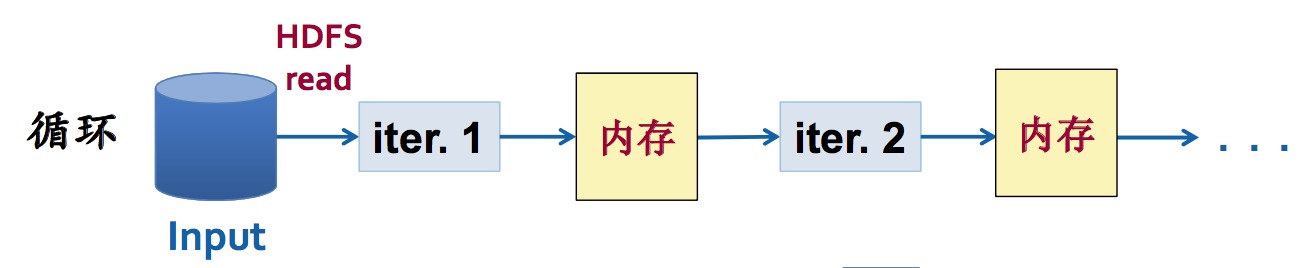
可以从HDFS中读数据,但是运算过程中 数据放在内存中(而不是像Hadoop MapReduce那样将中间的计算结果落到磁盘,然后又从磁盘读入)。内存计算的目标是低延迟的分析操作。
Hadoop MapReduce 的问题:通过HDFS进行作用间的数据共享,导致计算的中间结果都要落地到硬盘,代价太高。

Spark的思路:
- 内存容量越来越大
- 将数据放入多台机器的内存
- 避免计算中间结果在HDFS上读写的开销
RDD(Resilientt Distributed Data sets, 弹性分布式数据集)
- 一个数据集
- 只读,整个数据集创建之后不能修改
- 通常进行整个数据集的运算
RDD优点:
- 因为只读,并发控制变简单了
- 并不需要把RDD存储在stable storage(硬盘)上
RDD运算:
- Transformation
- 输入时RDD
- 输出也是RDD
- 仅记录,不运算
- Action
- 输入是RDD
- 输出可能是某种计算结果(例如,一个数值或者一列数值)
- 当遇到Action时,需要返回结果,才真正执行已经记录的前面的运算
RDD运算过程:读入内存一次,在内存中可以多次处理
Spark编程
- Scala,同时对Java、Python提供API
- Scala面向对象,函数式编程
- Scala运行在JVM上
容错/内存缓冲替换:当内存缓冲的RDD丢失的时候,可以重新执行记录的运算,重新计算这个RDD。
数据流系统
概念:在流动的数据上实时地完成处理。
Twitter的Apache Storm,大部分功能代码是Java和Clojure(Clojure一种Lisp,编译成为JVM bytecode)混合实现,提供的编程接口主要为Java,通过Thrift支持各种编程语言。