关系型数据库
关系型数据库:关系代数
事务处理
数据仓库:OLAP(在线联机分析处理)、ETL(extract、transform、load)。用不同处数据源收集数据,面向某个主题按维度集成到一起。
离线批处理
实时数据流处理
大数据的概念:3V。volume:数据量巨大。velocity:数据产生快。variety:数据种类繁多。
RDB、NoSQL、数据仓库、离线批处理(Hadoop)、内存计算(Spark)、实时流处理。
关系型数据库主要关系运算:
- selection(选择):用一个表中提取一些行
- projection(投影)
- join(连接)
连接的类型:
- 等值连接:如果R.a=S.b为条件的连接。如果a有m行的值为x,b有n行的值为x,那么这些行等值连接的结果由m*n个。
- 自然连接
- 内连接
- 左连接
- 右连接
- 全连接
分组、聚合函数。
having子句,在group by的基础上再进行选择。
1 | select Major, count(*) as Cnt from Student where Year >= 2012 and Year <= 2014 group by Major having Cnt >= 2; |
DBMS(数据库管理系统):是一种软件。
目前主流的3大商用关系型数据库:Oracle、SQL Server、DB2
关系型数据库系统架构:
- SQL语法解析(看SQL是否有语法错误)
- 查询优化(优化后SQL的语法树,即生成 查询计划 )
- 执行引擎(根据查询计划,访问数据,然后实现关系运算)
- 缓冲池(在内存中缓存硬盘的数据)
- 事务管理(目标ACID、写操作的log,并发读写时的lock)
- 数据存储和索引(如何高效地存储访问硬盘上的数据,数据结构)
数据库 vs 文件系统
文件系统
- 存储的是文件
- 通用的,可以存储任何数据和程序
- 文件是无结构的,是一串字节组成的
- 在操作系统的内核中实现
- 因为在内核中实现,所以对外提供基本的变成接口(系统调用),比如open、close、read、write。
数据库
- 存储的是数据表
- 存储的是特定结构的数据,比如关系型、KV型等
- 数据库是在用户程序中实现
- 对外提供DBMS的功能
硬盘上最小存储访问单位为一个扇区:512B。
文件系统访问硬盘的单位通常为4KB(和一个内存页的大小一样?)
RDBMS最小的存储单位是database page size。database page size 可以设置为1到多个文件系统的page,比如4KB、8KB、16KB等。
database page 的内部结构。由tuple组成。
顺序访问。顺序访问会顺序读取某个表中的每个page,然后对于每个page,顺序访问每个tuple。检查选择条件是否成立,成立就将其选择出来。
index(索引):有选择性的访问,区别于顺序访问。
- tree index:有序的,支持 点查询(a=1) 和 范围查询(a>1这样的条件在tree index下也能用上索引)
- hash index:无序的,只支持 点查询
树形索引实现的重要数据结构:B+树
B+树。每个节点是一个page。所有key都存在 叶子节点。非叶子节点 完全是起索引作用。
然后B+树相比B树,有一个非常重要的改进,就是叶子节点全部连起来了。
B+树的查找(搜索):用 根节点 到 叶子节点。每个节点中进行 二分查找。找到了叶子节点,就找到了匹配项。
用B+树搜索的代价:假设共有N个节点(key),每个节点中包含B个值,那么总的I/O次数=B+树的高度:O(logBN)。总的比较次数:每个节点内部二分查找O(log2B),O(logBN)*O(log2B)=O(log2N)。用B+树不用二叉树的优势在于可以极大减小索引查找时IO的次数。
当如节点,当节点慢了的时候,需要让B+树的节点分裂。
那么,这里有一个问题。一个建立了B+树索引的列,当查找的值为 NULL 的时候,是否会命中索引呢?
Does mysql index null values?。根据这个回答,MySQL其实在IS NULL这种写法上做了优化,将其当做某个常数值,借此达到了建立索引的效果。MySQL官方文档的解释:IS NULL Optimization
数据缓冲池:减少磁盘IO,提高性能。
访问的局部性:
- 时间局部性:同一个数据元素可能会在一段时间内多次被访问
- 空间局部性:位置相近的数据元素可能会被一起访问(page为读写单位)
数据库缓冲池 的 内存单元 分成database page大小的单元,每个内存单元可以缓冲一个数据库上的磁盘单元(database page)。
缓冲池的缓存替换策略,和OS内存换页比较像。通常是LRU,因为其是符合访问局部性原理的。
CLOCK算法
事务处理
ACID:
- 原子性:一个事务里的操作,要么全部执行,要么全部不执行。
- 一致性:从一个正确状态转换到另一个正确状态(比如转账前后),一致性这个概念很多时候是自己定义的。
- 隔离性:每个事务与其他并发事务互不影响。
- 持久性:事务commit之后,结果持久有效。
判断一组并发事务是否正确执行的标准:可串行化(并行执行结果=某个顺序的穿行执行结果)。
并发事务可能造成的问题:
- 读脏:比如,在T2 commit 之前,T1读了T2已经修改了但是没有commit 的数据。
- 不可重复读:在T2 commit 之前,T1写了T2已经读的数据并且T1已经在T2之前 commit,如果T2再次读同一个数据,那么将发现读取的是同的值。(不可重复读,即一个事务两次读到的东西不一致,然后可能导致逻辑错误)。
- 更新丢失:在T2 commit 之前,T1已经重写了T2已经修改了的数据。
MySQL 事务的4个隔离级别
- 读未提交:脏读、不可重复读、更新丢失都可能发生。
- 读已提交:不可重复读、更新丢失可能会发生。
- 可重复读:更新丢失可能发生。
- 串行化:完全安全的级别,但是这样会极大影响效率,死锁的发生概率也会极大地增加。
两大类解决方案:
悲观
- 假设:数据竞争可能经常出现
- 防止机制:采用某种机制确保数据竞争不会出现。比如,如果一个事务 T1可能和正在运行的其它事务有冲突,那么就让这个T1等待,一直等到有冲突的其它所有事务都完成为止,才开始执行。
乐观
- 假设:数据竞争很少见
- 检查机制:
- 允许所有事务都直接执行
- 但是事务不直接修改数据,而是把修改保留起来
- 当事务结束时,检查这些修改是否有数据竞争。没有竞争,成功结束,真正修改数据;如果有竞争,丢弃结果,重新计算。
悲观并发控制机制:使用加锁实现。对事务中的读写数据进行加锁,通常采用 两阶段加锁(2PL)。
两阶段加锁 的过程:
- 在Transaction开始时,对每个需要访问的数据加锁。如果不能加锁,就一直等待,直到加锁成功。
- 执行Transaction的内容。
- 在Transaction commit前,集中对这个事务加锁的数据进行解锁
- 提交事务
有一个集中的加锁阶段和一个集中的解锁阶段,由此得名。
思考的一个问题,锁的粒度?对表、行加锁?
读锁?写锁?
S锁(共享锁):保护读操作
X锁(排它锁):保护写操作
意向锁(Intent Locks):
- IS(意向共享锁):IS(a)将对a下面更细粒度的数据元素进行读
- IX(意向排它锁):IX(a)将对a下面更细粒度的数据元素进行写
为了得到S、IS:,所有祖先必须为IS或IX;为了得到X、IX,所有祖先必须为IX。
乐观并发控制方案:Snapshot Isolation等。
Snapshot Isolation
- snapshot:一个时间点的数据库状态(快照)。
- 做法:在事务开始的时候,读这个snapshot的数据,将事务的更新先临时保存起来,在commit时检查版本有无冲突,有冲突就abort这个事务,然后重试。先提交的事务win。

MVCC(Multiversion Concurrency Control)是 Snapshot Isolation 的一种实现。
某些情况下,MVCC并不是 串行等价 的。入下图:

事务的 持久性 如何实现?
解决方案:WAL(Write Ahead Logging)
事务日志(Transactional Logging):对事务中每个写操作会产生一个日志记录,对事务的commit会产生一个commit日志记录,对事务的abort会产生一个abort日志记录。
日志记录 被追加(append)到日志文件末尾。日志文件 是一个 append-only 的文件,每条日志记录有一个LSN(Log Sequence Number,是一个不断递增的整数,唯一代表一个记录;每产生一个日志记录,LSN +1),日志文件 中 日志记录 按照 LSN 顺序添加。
什么是Write-Ahead?
- Logging总是 优先于 实际的操作
- Logging相当于是意向,先记录意向,然后再实际的写操作
- 先记录commit或abort的日志记录,然后再commit或abort
根据commit日志,知道事务是否已经commit。如果因为掉电导致事务没有提交,可以根据日志记录的写操作进行恢复。
保证事务日志的持久性:write + flush。必须执行一个写操作,然后用 flush 保证写操作确实写到硬盘上了,并且等待 flush 结束。
如果一个事务要修改的记录很多,那么一个一个将日志写到硬盘肯定会非常慢。可以在在内存中分配一个 缓冲区 (Log Buffer),批量的写多条日志记录。
检查点(Checkpoint)
使用 检查点 机制可以使崩溃恢复时间可控。如果没有checkpoint,可能需要读整个日志,redo/undo很多工作。定期执行checkpoint。
日志文件 不可能无限增长。当事务完成,更新操作写入到磁盘后,就可以把这之前的日志记录都删除掉。
当事务正在进行的时候,机器崩溃了,然后就有一个 Crash Recovery 机制。
ARIES算法:
- 分析阶段(找到日志的最后一个 检查点,找到日志崩溃点,确定崩溃时的活跃事务和脏页)
- redo阶段(把系统恢复到崩溃前瞬间的状态)
- undo阶段(清楚未提交的事务的修改)
数据仓库
关键词:OLAP、ETL
特点:
- 集成的,采集自多个数据源
- 面向主题的,支持决策
- 反映历史变化
- 能够按维度查询
- 只读(没有修改操作),分析操作
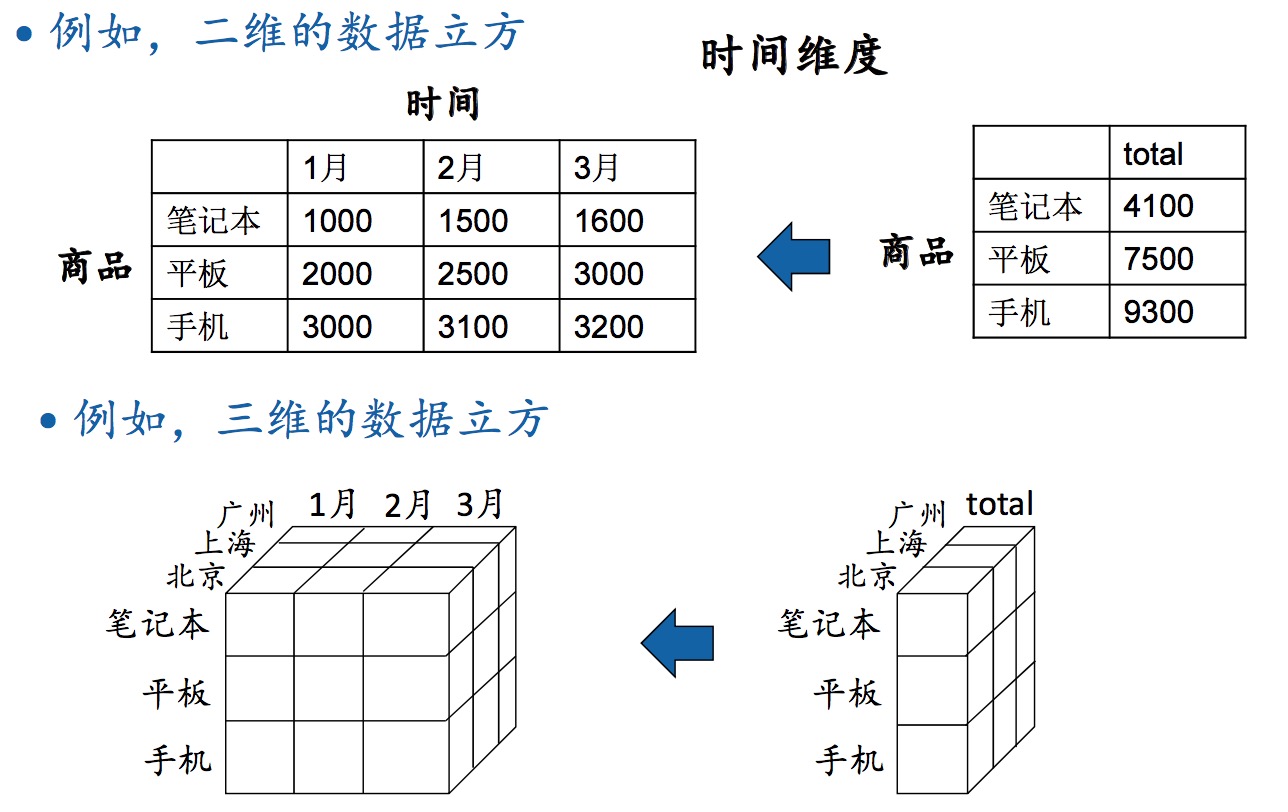
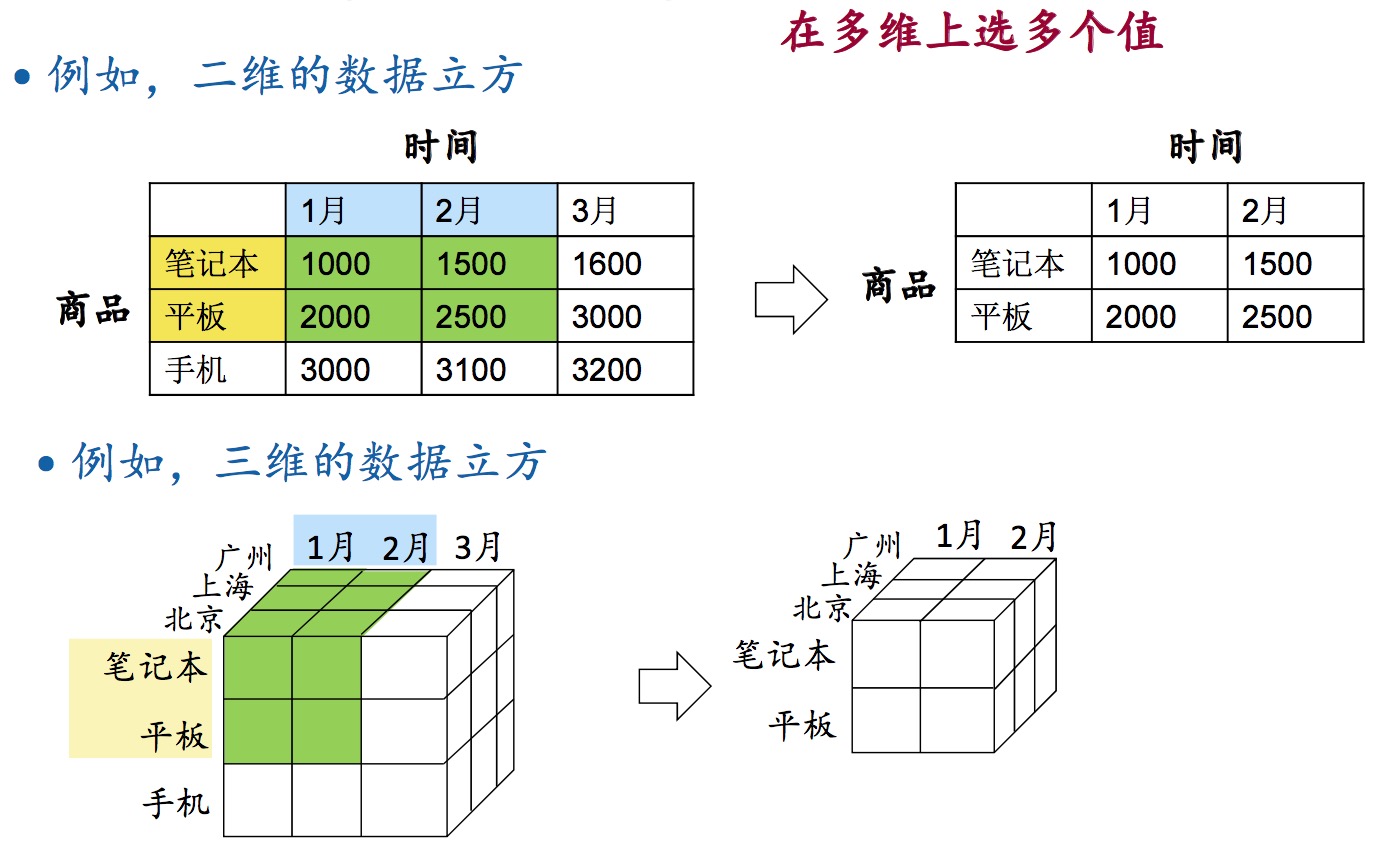
数据仓库是OLAP的基础。OLAP的基本数据模型是多维矩阵(数据立方体)。
数据立方体 的操作:roll up(上卷)、drill down(下钻)。
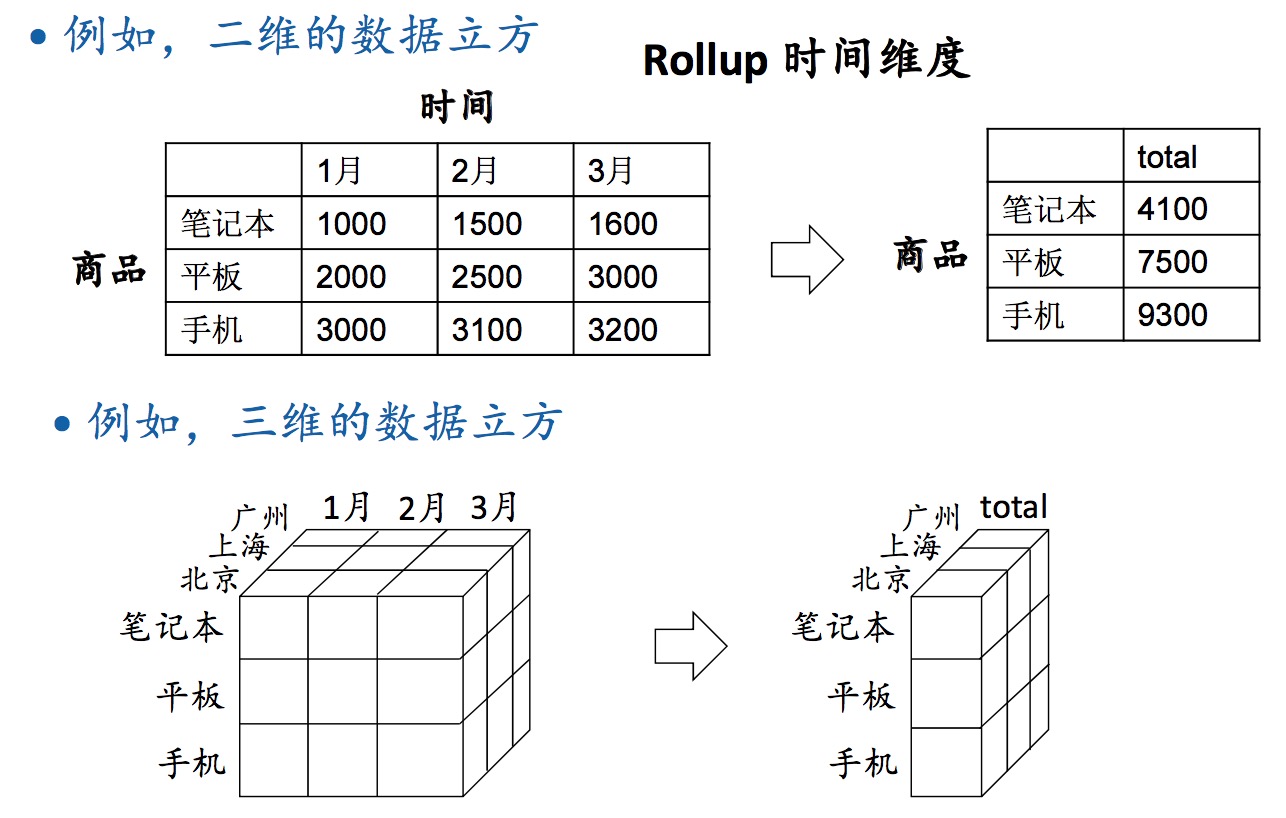
在一个维度上有可能定义层级:
- 时间:年-月-日
- 地点:国-省-市
roll up:在某个维度上求和,降维,从细粒度到粗粒度。drill down:将某个维度的和分解,增维,从粗粒度到细粒度。
slice(切片):在某维上选一个值。
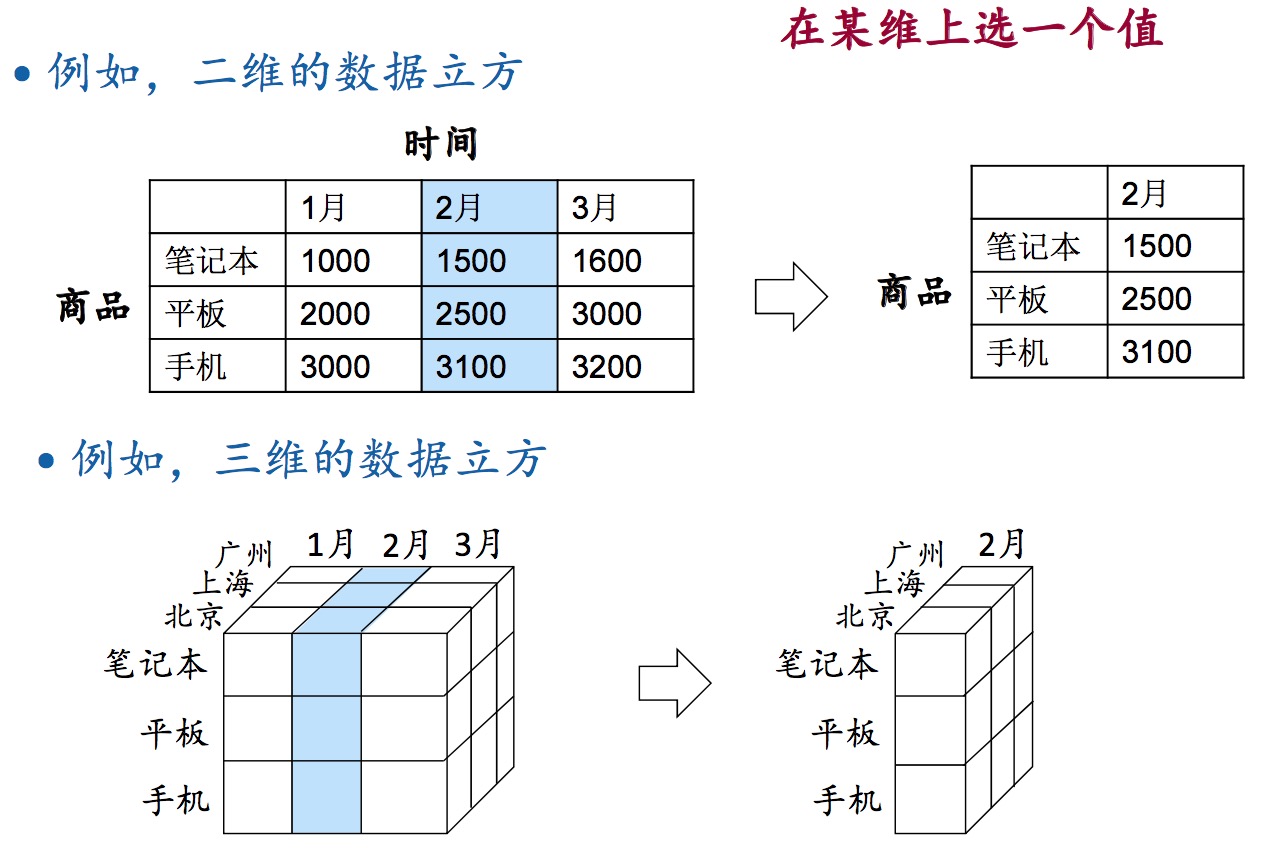
dice(切块):在多维上选多个值。
分布式数据库
关键技术:
- Partition(划分):将数据分布到多台服务器上
- Replication(备份):提高可用性、容灾
分布式事务:一个事务读写的数据分布式在不同的机器上。
两阶段提交(2PC)